


Copilot, a new code-generation tool from GitHub and OpenAI, is now a component of Microsoft Studio Code and autocompletes code snippets. Copilot is built on Codex, a GPT-3 product that was introduced a year ago. The buzz surrounding GPT-3 appears to be continuing, so we decided to go over the specifics step by step. Check it out.
What exactly is GPT-3?
GPT-3 is an abbreviation for Generative Pre-trained Transformer 3, and it is the third iteration of the language model released by Open AI in May 2020. It is generative in the sense that GPT-3 can produce large phrases of unique text as output. Most neural networks are only capable of spitting out yes or no answers or short words. Pre-trained indicates that the language model was not created with any unique domain expertise, yet it is capable of performing domain-specific tasks such as translation. As a result, GPT-3 is the most inventive language model ever created.
So, what exactly is Transformer? Simply explained, it is the neural network architecture developed by Google scientists in 2017, and it employs a self-attention mechanism that is well-suited to language comprehension. Transformer became a testing environment for GPT-1 and Google's BERT, another amazing language model, when the attention mechanism permitted a breakthrough in the NLP space in 2015. In essence, attention is a function that estimates the likelihood of the next word arriving amid the others.
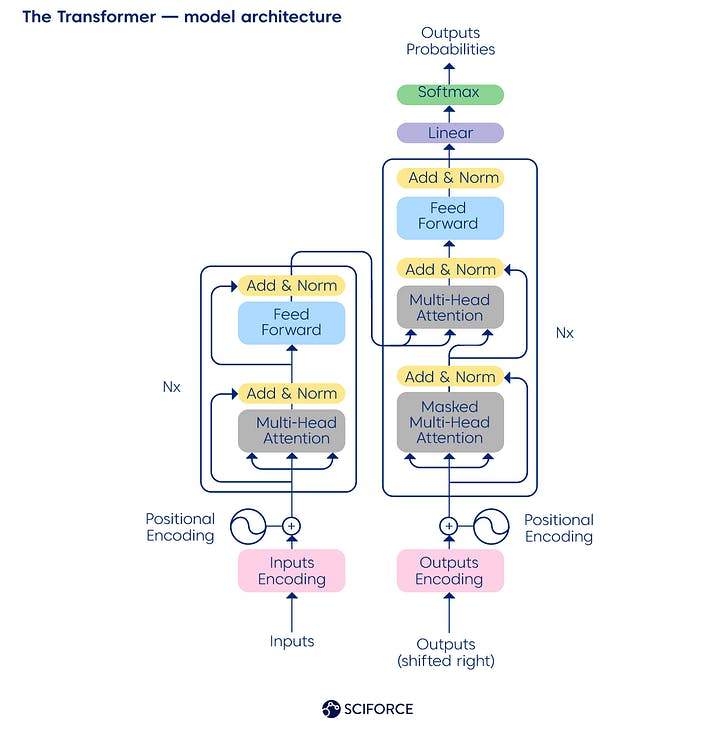
Structure of a typical Transformer
So what makes GPT-3 so special? The GPT-3 language model comprises 175 billion parameters, which are the values that a neural network optimizes during training (compare with 1,5 billion parameters of GPT-2). As a result, this language model offers a high potential for automation across a wide range of sectors, from customer service to document preparation. You could experiment with the GPT-3 Playground beta on your own.
How can I put GPT-3 to use in my applications? You can join the queue as of July 2021, when the firm will be able to offer a private beta version of its API on a LmaS basis (language-model-as-a-service).
These are some samples of GPT-3's work that you may have heard of: GPT-3 writes beautiful literature. Gwern, the author of gwern.net and a GPT-2 and GPT-3 experimenter, claims that "GPT-3, however, is not only a numeric tweak generating "GPT-2 but better" – it is qualitatively distinct." The benefit of GPT-3 for text generation is that you don't have to train anything in the traditional method. Instead, you should create GPT-3 prompts to teach it whatever you wish.
Sharif Shameem used GPT-3 for debuild, a platform that generates code as per request. You could type a request like “create a watermelon-style button” and grab your code to use for an app. You could even use GPT-3 to generate substantial business guidelines, as @zebulgar did.
How does GPT-3 work?
Let us look under the hood and define the nuts and bolts of GPT-3.
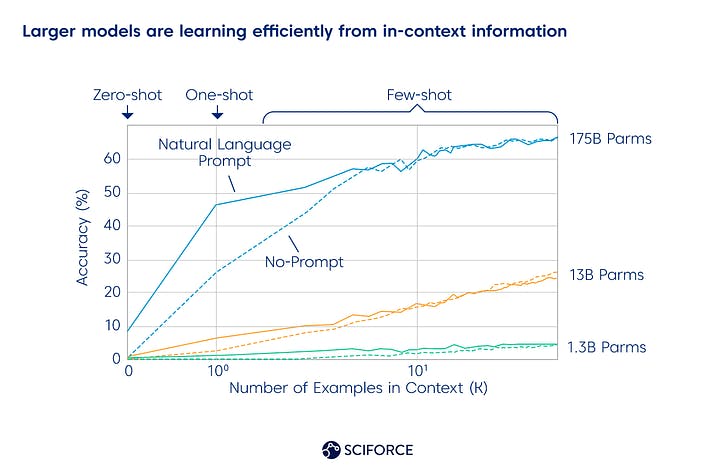
Larger models are learning efficiently from in-context information
To put it simply, GPT-3 evaluates the likelihood of one word appearing in the text given the presence of another in the text. It's referred to as the conditional probability of words. For example, consider the word chair in the following sentences: "Margaret is organizing a garage sale... "Maybe we could buy that old __ " is far more likely to materialize than, say, an elephant. That is, the likelihood of the word chair appearing in the prompted text is greater than the likelihood of an elephant.
When ingesting millions of sample texts, GPT-3 uses some type of data compression to transform the words into vectors, or numeric representations. The language model will then unpack the compressed text into human-friendly phrases. Thus, compressing and decompressing text develops the model’s accuracy while calculating the conditional probability of words.

The dataset used to train GPT-3
Since GPT-3 is high-performing in the “few-shot” settings, it can respond in a way consistent with a given example piece of text that has never been exposed before. Thus, it only needs a few examples to produce a relevant response, as it has already been trained on lots of text samples. Check out the research paper for more technical details: Language Models are Few-Shot Learners.
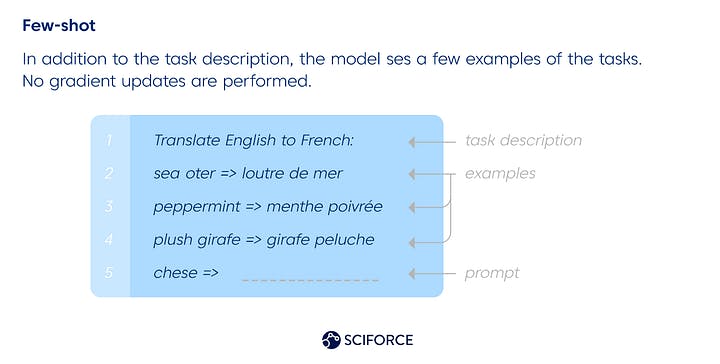
Because it has previously been trained on a large number of text samples, the few-shot model requires just a few instances to generate an appropriate response. The diagram depicts the mechanics of English-to-French translation.
When the language model's conditional probability is as accurate as feasible after training, it can predict the next word when given an input word, phrase, or fragment as a prompt. Formally speaking, the prediction of the following word is related to natural language inference.
What exactly can GPT-3 do?
GPT-3 is essentially a text predictor; its output is a statistically probable response to the given input, based on the data it was trained on before. Nevertheless, some critics argue that GPT-3 is not the greatest AI system for answering questions and summarising material. GPT-3 is average in comparison to SOTA (state-of-the-art) systems for each NLP job individually, but it is considerably more generic than any prior system, and future ones will be similar to GPT-3.
GPT-3, in general, can accomplish NLP tasks after a few instructions. It performed well in the following tasks using the few-shot settings:
Language modeling
GPT-3 demonstrated a perplexity of 20,5 (defines how well a probability language model predicts a sample) under the zero-shot circumstances on the Penn Tree Bank (PTB). The closest rival, BERT-Large-CAS, boasts 31,3.
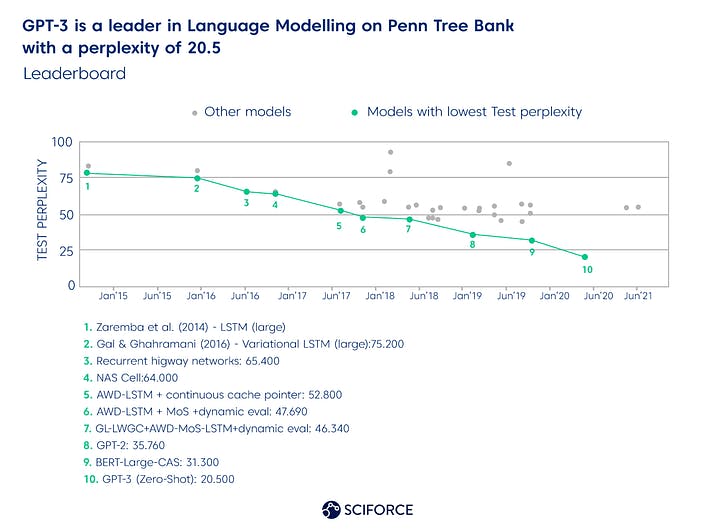
GPT-3 is a leader in Language Modelling on Penn Tree Bank with a perplexity of 20.5
GPT-3 additionally achieves 86.4% accuracy (an 18% improvement over prior SOTA models) in the few-shot conditions when running the LAMBADA dataset test. The model predicts the final word in the sentence for this test, requiring "reading" of the entire paragraph.
Critical note: GPT-3 proved these conclusions using fill-in-the-blank scenarios such as:
"Alice has a buddy named Bob. Alice went to see her friend_________. Bob
George purchased some baseball equipment, including a ball, a glove, and a______."
Moreover, researchers report about 79,3% accuracy while picking the best ending of a story while on the HellaSwag dataset in the few-shot settings. And it demonstrated 87,7% accuracy on the StoryCloze 2016 dataset (which is still “4.1% lower than the fine-tuned SOTA using a BERT-based model”).
Closed book question answering
… or testing broad factual knowledge with GPT-3. As per the GPT-3 research paper, it was tested on Natural Questions, WebQuestions, and TriviaQA datasets, and the results are the following:
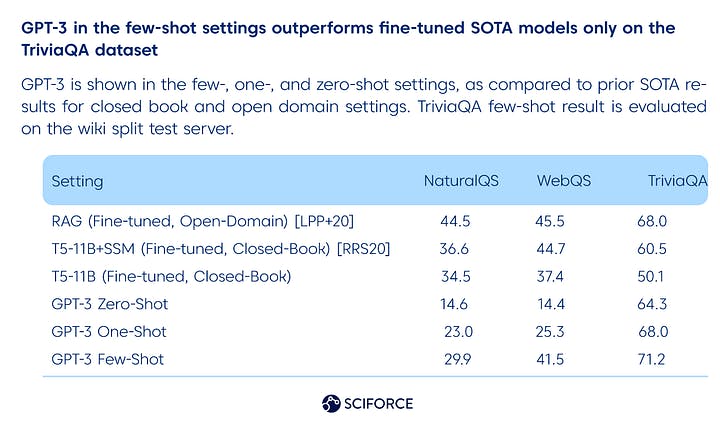
GPT-3 in the few-shot settings outperforms fine-tuned SOTA models only on the TriviaQA dataset
Translation
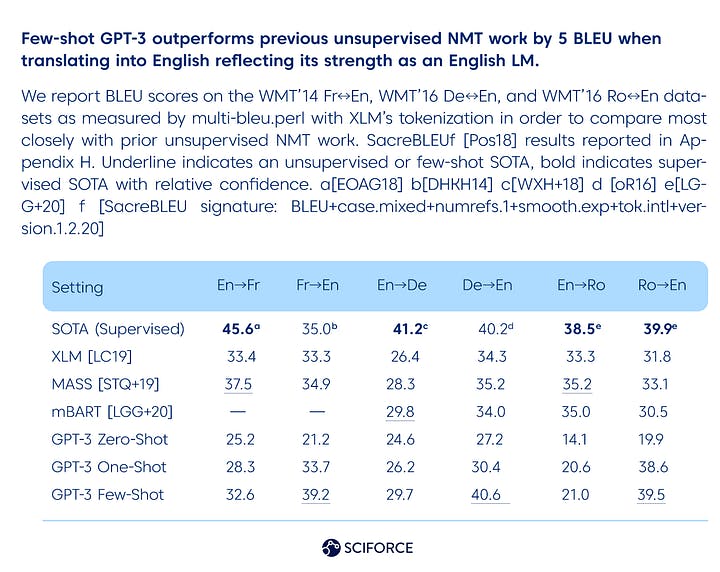
In terms of translation, supervised SOTA neural machine translation (NMT) models are undisputed leaders. GPT-3, on the other hand, demonstrates its power as an English LM, particularly when translating into English. According to the researchers, "GPT-3 greatly outperforms past unsupervised NMT work when translating into English but underperforms when translating the opposite way."
In general, there is a smooth rising trend with model capacity across all three language models examined (English in combination with French, German, and Romanian).
Winograd-Style Assignments
Winograd-style tasks are traditional NLP tasks that determine word pronoun referencing in sentences that are grammatically unclear but semantically unambiguous for humans. Fine-tuned algorithms have recently achieved human-like performance on the Winograd dataset, although they still behind the more complicated Winogrande dataset.
The following are the GPT-3 results: "On Winograd GPT-3 obtains 88.3%, 89.7%, and 88.6% in zero-shot, one-shot, and several-shot conditions, respectively, demonstrating no evident in-context learning but attaining good results just a few points behind state-of-the-art and estimated human performance."
Reasoning from experience
GPT-3 does not outperform fine-tuned SOTA algorithms in physical or scientific reasoning:
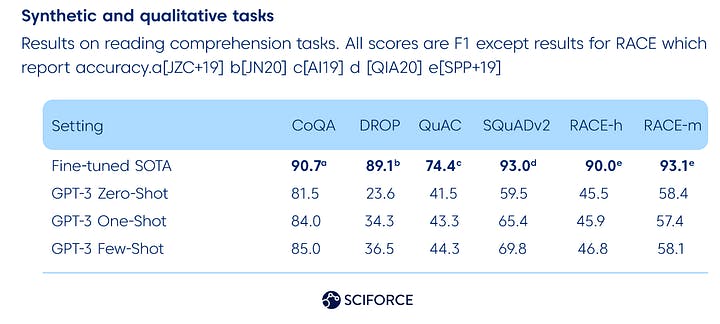
Synthetic and qualitative tasks
GPT-3 is not that good at arithmetic still, since the results are the following:
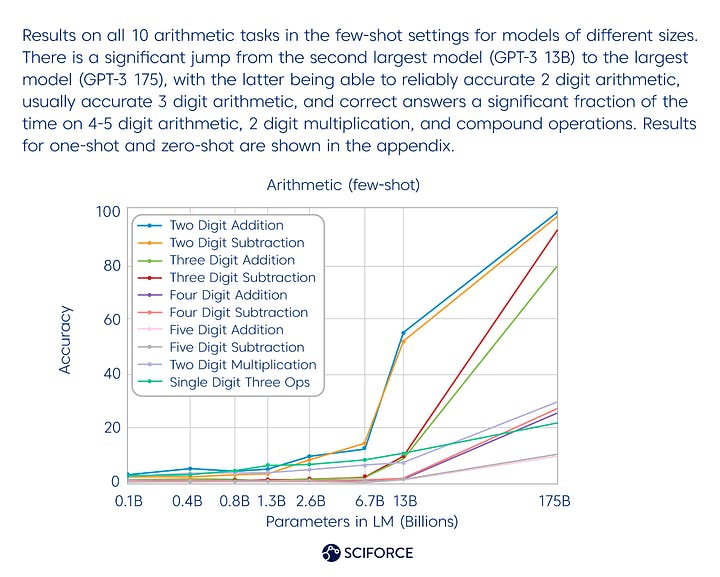
When it comes to news article production, however, human recognition of GPT-3 written news (few-shot settings) is similar to chance — 52% mean accuracy.
What are GPT-3's limitations?
Even Open AI Founder Sam Altman has tweeted that GPT-3 is overhyped, and this is what the researchers have to say:
Text synthesis and a variety of NLP tasks
GPT-3 is not excellent at text synthesis; while the overall quality of the produced content is great, it begins to repeat itself at the document level or in extended stretches.
It is also lagging in the domain of discrete language tasks, having difficulty within “common sense physics”. Thus, it is hard for GPT-3 to answer the question: “If I put cheese into the fridge, will it melt?” GPT-3 has some notable gaps in reading comprehension and comparison tasks.
Limitations in structure and algorithm
GPT-3 can improve on tasks that gain experimentally from bi-directionality. Fill-in-the-blank activities, tasks that need going back and comparing two pieces of text, or tasks that demand re-reading or carefully digesting a long section and then creating a very brief answer," according to the study.
Versions such as the GPT-3 are both expensive and inconvenient.
Models like GPT-3 have a wide range of abilities and might become "overqualified" for some activities. Also, it is a computationally intensive model: "training the GPT-3v175B consumed several thousand petaflop/s-days of compute during pre-training, compared to tens of petaflop/s-days for a 1.5B parameter GPT-2 model," according to the researchers.
GPT-3 is skewed
Because the algorithm was trained on human-generated internet information, there are still issues with bias, justice, and representation. As a result, GPT-3 can produce biased or stereotypical information. Yet, you may find a lot of information about it online or in the study paper. The writers are thinking about it.
Bottom line
GPT-3 is a peek at the bright future in NLP, assisting in the generation of code, meaningful text fragments, translation, and doing well in a variety of tasks. It also has limits and ethical difficulties, such as creating biased text fragments. Overall, we are observing something intriguing, as we have always done in NLP.
Thank you for taking the time to read this blog about GPT-3. We hope it has provided you with valuable insights and a deeper understanding of this powerful language model. If you have any questions or comments, please feel free to leave them below. We appreciate your support and look forward to bringing you more informative content in the future.